In a groundbreaking fusion of ancient humanities and cutting-edge technology, an international team of researchers is utilizing artificial intelligence to unravel one of the most enduring mysteries of biblical scholarship: the authorship of the Hebrew Bible’s earliest texts. The study, spearheaded by Shira Faigenbaum-Golovin, an assistant research professor of Mathematics at Duke University, introduces a novel AI-based statistical approach that sheds new light on the complex tapestry of the Bible’s first nine books, known collectively as the Enneateuch.
For centuries, scholars have debated the origins and authorship of biblical texts, attempting to differentiate the voices of different scribes and editorial layers within a sacred and historically pivotal manuscript. Traditional methods have heavily relied on expert linguistic intuition and qualitative textual criticism, but the advent of AI offers a chance for quantitative, data-driven analysis. Faigenbaum-Golovin’s team devised a statistical model that analyzes subtle variances in language patterns—specifically, the usage frequencies of common words and sentence structures—to distinguish between distinct scribal traditions embedded within the text.
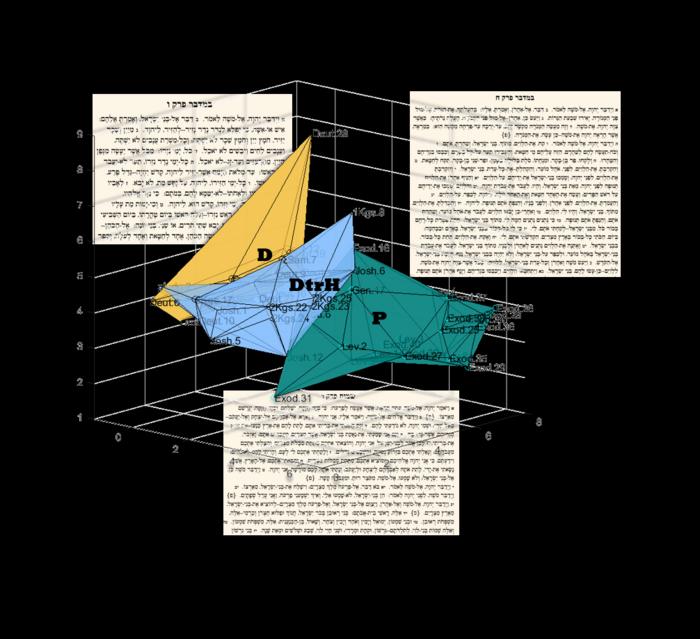
This project is not merely a proof of concept but provides a robust methodology for identifying three primary writing styles that traverse the Enneateuch. These three scribal traditions, depicted visually in the team’s graphical analyses as yellow, blue, and green corpora, correspond closely with established scholarly divisions: the Deuteronomistic History, the priestly writings of the Torah, and the texts of Deuteronomy itself. What makes this research exceptional is that the AI system does not function as a black box; it offers transparency by highlighting the specific linguistic features that informed each classification, bridging the gap between human interpretative skill and machine precision.
The origins of this interdisciplinary venture date back to 2010, when Faigenbaum-Golovin began collaborating with Israel Finkelstein, head of the School of Archaeology and Maritime Cultures at the University of Haifa. Their pioneering work involved applying mathematical and statistical techniques to analyze handwriting inscriptions found on ancient pottery dating from approximately 600 B.C. By comparing letter shapes and inscribed styles across pottery fragments, they uncovered patterns that offered insights relevant to dating biblical texts, a discovery that famously graced the front page of The New York Times and set the stage for their present research trajectory.
Expanding their team to include archaeologists, biblical scholars, physicists, mathematicians, and computer scientists, the researchers applied their model to three major biblical sections: the five books of Moses, the Deuteronomistic History spanning Joshua through Kings, and priestly texts within the Torah. Using word frequency analysis paired with pattern recognition of sentence structures, their statistical approach reaffirmed the scholarly consensus that Deuteronomy and the historical books share closer stylistic similarities compared to the priestly writings, an important validation of the model’s accuracy and relevance.
One of the research’s most striking revelations is the model’s sensitivity to differences even among the most elementary words such as “no,” “which,” or “king.” These seemingly mundane variances revealed deep stylistic divides, underscoring that writing style differences transcend thematic or narrative content and instead inhabit the fundamental layers of language usage. Thomas Römer, a team member from the Collège de France, emphasized the model’s ability to pinpoint these stylistic nuances, signaling a quantitative breakthrough that depends on the frequency of tiny linguistic elements rather than just content or subject matter.
To rigorously test their model, the team analyzed 50 chapters across the Enneateuch, each previously categorized by biblical scholars into identifiable writing traditions. The AI system successfully allocated each text segment to one of the three recognized styles using a quantitatively derived formula, confirming its efficacy in parsing complex ancient literary data. The real power of this method, however, lies in its subsequent application to more controversial biblical passages whose authorship has been historically disputed, where it was able to suggest probable origins along with explicit reasons based on word usage patterns.
A fundamental challenge confronted by the researchers was the nature of biblical texts themselves, which have undergone countless edits and revisions over centuries. Identifying segments that preserve original language is akin to finding needles in a haystack, particularly since some passages are very short, often only a handful of verses long. Unlike modern text corpuses with abundant data, the limited size and modified nature of biblical texts make standard machine learning algorithms ineffective or unreliable, compelling the team to develop customized analytical tools tailored for sparse, fragmentary data.
This new methodology bypasses traditional machine learning’s reliance on massive training datasets by engaging in direct statistical comparisons of linguistic features, principally focusing on how frequently certain words or word roots (lemmas) appear, as well as evaluating sentence constructions. This approach allows the AI not only to identify consistent stylistic fingerprints indicative of authorship but also to maintain high confidence in the statistical significance of its results, addressing a common criticism regarding data scarcity in ancient text analysis.
Among the most surprising findings was the analysis of the Ark Narrative in the Books of Samuel. Though the stories in 1 Samuel and 2 Samuel revolve around similar themes and are often treated as a single unit, the AI revealed distinct writing styles for each. The text in 1 Samuel defied alignment with any of the three main corpora, suggesting a unique tradition or redaction history, whereas 2 Samuel bore a clear stylistic resemblance to the Deuteronomistic History. This nuanced insight exemplifies the potential of AI to challenge long-held assumptions and invite reconsideration of biblical composition history.
Looking ahead, Faigenbaum-Golovin envisions far-reaching applications for this innovative technique beyond biblical studies. Its ability to authenticate writings and identify authorship from fragments can aid in historical document validation—potentially settling disputes about the authenticity of manuscripts purportedly linked to historical figures such as Abraham Lincoln. By combining rigorous mathematical modeling with linguistic expertise, this AI framework could serve as a vital tool for historians, archivists, and literary scholars confronting questions of provenance and forgery.
Reflecting on the collaborative nature of the project, Faigenbaum-Golovin expressed deep satisfaction with the blending of disciplines, highlighting the remarkable synergy between the scientific and humanities communities. The partnership, bringing together statisticians, archaeologists, linguists, and computer scientists, allowed the team to tackle complex problems that no single field could resolve alone. This intersectional approach represents a new paradigm, not only for biblical scholarship but also for the study of ancient texts more broadly.
Currently, the team is extending their research to examine other ancient manuscripts, including the Dead Sea Scrolls, applying their AI-driven methodology to uncover new layers of authorship, chronology, and textual relationships. This ongoing work promises to continue bridging millennia-old traditions with 21st-century computational power, opening a new chapter in the study of humanity’s shared textual heritage.
As AI increasingly permeates every facet of modern life—from medicine to finance and the arts—this pioneering research demonstrates its transformative potential in the realm of ancient textual analysis. The fusion of advanced mathematics, computer science, and humanities scholarship heralds a future where enigmatic scriptures may be more transparently understood than ever before, unlocking the authorship mysteries that have puzzled scholars for centuries.
Subject of Research: Not applicable
Article Title: Critical biblical studies via word frequency analysis: Unveiling text authorship
News Publication Date: 3-Jun-2025
Web References: https://doi.org/10.1371/journal.pone.0322905
References: Faigenbaum-Golovin S, Kipnis A, Bühler A, Piasetzky E, Römer T, Finkelstein I (2025) Critical biblical studies via word frequency analysis: Unveiling text authorship. PLoS One 20(6): e0322905. https://doi.org/10.1371/journal.pone.0322905
Image Credits: Faigenbaum-Golovin et al.

{kind=link}