In the rapidly evolving landscape of language assessment, a groundbreaking study from Japan Advanced Institute of Science and Technology (JAIST) introduces a sophisticated, multimodal framework to revolutionize how spoken English proficiency is evaluated. Moving beyond traditional, monolithic testing methods that primarily rely on isolated modalities, this new approach leverages synchronized audio, visual, and textual data to deliver a more nuanced, interpretable assessment of an individual’s communicative competence. The research team, led by Professor Shogo Okada alongside Assistant Professor Candy Olivia Mawalim and collaborators, published these findings in the prestigious journal Computers and Education: Artificial Intelligence on March 20, 2025, offering a formidable advancement in automated language evaluation, particularly pertinent for adolescent learners.
Spoken English proficiency has long been regarded as a crucial factor determining academic achievement and professional success. Historically, its assessment involved labor-intensive exams with subjective human raters who evaluated facets such as grammar, vocabulary, and pronunciation. However, the limitations inherent in these conventional methods — namely cost, scalability, and consistency — have spurred a growing interest in automated solutions. Notably, most existing automated systems focus predominantly on a single modality, such as textual transcripts or acoustic signals, often in monologue-style tests that fail to capture the dynamics of real-life conversations. This gap motivated the JAIST research group to develop an integrative assessment framework that reflects complex speaking scenarios involving interactive communication.
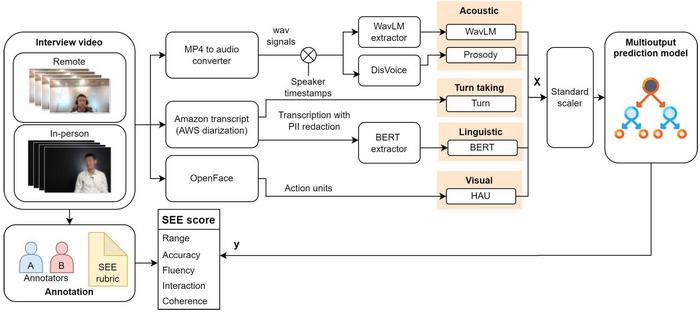
Central to this innovation is the deployment of a novel Spoken English Evaluation (SEE) dataset, meticulously curated through open-ended, high-stakes interviews involving adolescents aged 9 to 16. This unique dataset combines synchronized audio recordings, high-definition video capturing facial expressions and gestures, and verbatim text transcripts, all collected by Vericant—a real service provider specializing in language assessment. Crucially, expert evaluators affiliated with the Education Testing Service (ETS) assigned detailed speaking-skill scores across multiple dimensions, providing a rich foundation for supervised learning algorithms. The ability to correlate multimodal features to these expert scores allows for unprecedented interpretability and granularity in assessment outcomes.
Professor Okada’s team harnessed state-of-the-art machine learning tools to integrate diverse data streams encompassing acoustic prosody, facial action units, and pragmatic linguistic patterns such as turn-taking dynamics. The multioutput learning framework employs the Light Gradient Boosting Machine (LightGBM) algorithm to synthesize these heterogeneous inputs effectively. Compared to unimodal or isolated analyses, this multimodal approach achieved a remarkable overall prediction accuracy of approximately 83% on the SEE score, demonstrating the strength of combining complementary information sources. Such performance not only validates the model’s robustness but also signifies a diagnostic leap in evaluating complex social and communicative competencies.
Beyond mere accuracy, the system captures the essence of spontaneous, creative communication within open-ended interviews, as emphasized by Dr. Candy Olivia Mawalim. This aspect is critical because conventional assessments often restrict candidates to rehearsed responses, thereby overlooking their adaptive sociolinguistic skills. By modeling these multifaceted dimensions of speech, the framework enables evaluators to better understand individual learners’ strengths and weaknesses across pronunciation, fluency, interactional competence, and content relevance, thus facilitating more personalized feedback and targeted pedagogical interventions.
Intriguingly, the researchers applied deep linguistic modeling using Bidirectional Encoder Representations from Transformers (BERT) to analyze the sequential flow of utterances during the interviews. The findings revealed that the initial utterance bears significant predictive weight in determining overall spoken proficiency, underscoring the psychological and communicative importance of first impressions in spoken exchanges. Moreover, the study explored the impact of external interview conditions such as interviewer speech patterns, gender, and the modality of the interview (in-person versus remote). These variables demonstrated substantive effects on the coherence and quality of responses, highlighting the contextual sensitivities vital for interpreting spoken language proficiency assessments accurately.
The practical implications of this research stretch far beyond academic inquiry. As Professor Okada elucidates, the framework offers actionable insights for diverse stakeholders—students can receive tailored feedback directing their learning paths, while educators gain tools to customize instruction according to individual communicative profiles. This personalization elevates language teaching from generic criteria toward student-centered strategies that nurture important soft skills like public speaking, interpersonal dialogue, and emotional expressiveness. The resultant pedagogical innovations could transform teaching methodologies, equipping students with holistic communication competencies indispensable in globalized environments.
Dr. Mawalim envisions a future where AI-driven multimodal assessments become ubiquitous in educational ecosystems worldwide. These technologies promise not only to streamline evaluation but also to provide real-time, interpretable feedback that adapts dynamically to each learner’s communicative style. Such integration could catalyze the development of immersive language learning environments incorporating virtual reality, interactive avatars, and intelligent tutoring systems, all calibrated through multimodal performance metrics. This convergence of AI, linguistics, and education paves the way for a paradigm shift in soft skill development, fostering essential career and life skills seamlessly alongside language mastery.
Technically, the methodological advances include precise extraction of acoustic features such as pitch, intensity, and rhythm patterns, alongside computer vision techniques like facial action unit detection that interpret microexpressions and engagement levels. The algorithmic fusion of these signals within a multioutput supervised learning model enables simultaneous predictions across structured skill indices, a notable departure from traditional one-dimensional scores. By embracing the complexity of spoken communication, the system accounts for turn-taking behavior, hesitation markers, and nonverbal feedback, elements conventionally neglected yet fundamentally shaping conversational efficacy.
This research addresses a crucial gap: the scarcity of datasets and computational techniques tailored for interactive speech assessment, especially among young adolescents in authentic interview contexts. The interdisciplinary collaboration between speech scientists, educational experts, and AI researchers facilitated the creation of a benchmark that can standardize future work in this domain. Furthermore, by incorporating educational testing authority supervision, the framework ensures alignment with global assessment standards, bolstering the credibility and applicability of machine-generated proficiency evaluations.
In conclusion, the multimodal speaking skill assessment framework developed by the JAIST team epitomizes a forward-thinking approach to language evaluation, embedding technical sophistication and pedagogical relevance. By integrating multimodal signals, employing advanced machine learning algorithms, and situating the assessment within realistic social interactions, this research transcends existing paradigms. It charts a promising trajectory towards highly accurate, interpretable, and context-sensitive evaluations, poised to transform educational practices and empower a new generation of communicators worldwide.
Subject of Research: Automated multimodal assessment of spoken English proficiency among young adolescents integrating audio, visual, and textual data.
Article Title: Beyond accuracy: Multimodal modeling of structured speaking skill indices in young adolescents
News Publication Date: March 20, 2025
Web References:
http://dx.doi.org/10.1016/j.caeai.2025.100386
References:
Mawalim, C. O., Leong, C. W., Sivan, G., Huang, H-H., & Okada, S. (2025). Beyond accuracy: Multimodal modeling of structured speaking skill indices in young adolescents. Computers and Education: Artificial Intelligence. https://doi.org/10.1016/j.caeai.2025.100386
Image Credits: Candy Olivia Mawalim of JAIST
Keywords:
Educational assessment, Communications, Linguistics, Artificial intelligence

{kind=link}