{kind=link}
Understanding the 3D structure of scenes is an essential topic in machine perception, which plays a crucial part in autonomous driving and robot vision. Traditionally, this task can be accomplished by structure from motion and with multi-view or binocular stereo inputs. Since stereo images are more expensive and inconvenient to acquire than monocular ones, solutions based on monocular vision have attracted increasing attention from the community. However, monocular depth estimation is generally more challenging than stereo methods due to scale ambiguity and unknown camera motion. Several works have been proposed to narrow the performance gap.

Credit: Beijing Zhongke Journal Publising Co. Ltd.
Understanding the 3D structure of scenes is an essential topic in machine perception, which plays a crucial part in autonomous driving and robot vision. Traditionally, this task can be accomplished by structure from motion and with multi-view or binocular stereo inputs. Since stereo images are more expensive and inconvenient to acquire than monocular ones, solutions based on monocular vision have attracted increasing attention from the community. However, monocular depth estimation is generally more challenging than stereo methods due to scale ambiguity and unknown camera motion. Several works have been proposed to narrow the performance gap.
Recently, with the unprecedented success of deep learning in computer vision, convolutional neural networks (CNNs) have achieved promising results in the field of depth estimation. In the paradigm of supervised learning, depth estimation is usually regarded as a regression or classification problem, which needs expensive labeled datasets. By contrast, there are also some successful attempts to execute monocular depth estimation and visual odometry prediction together in a self-supervised manner by utilizing cross-view consistency between consecutive frames. In most prior works of this pipeline, two networks are used to predict the depth and the camera pose separately, which are then jointly exploited to warp source frames to the reference ones, thereby converting the depth estimation problem to a photometric error minimization process. The essence of this paradigm is utilizing the cross-view geometry consistency from videos to regularize the joint learning of depth and pose.
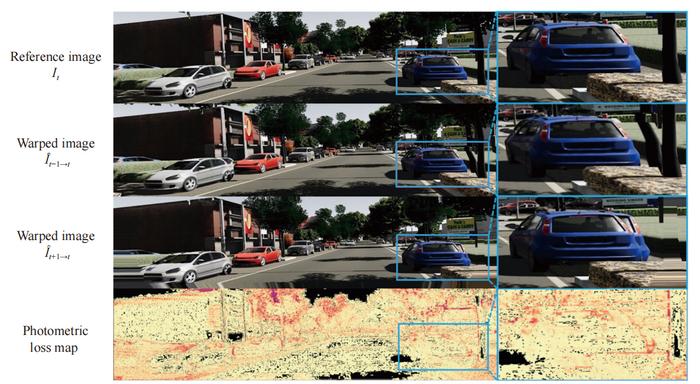
Previous self-supervised monocular depth estimation (SS-MDE) works have proved the effectiveness of the photometric loss among consecutive frames, but it is quite vulnerable and even problematic in some cases. First, the photometric consistency is based on the assumption that the pixel intensities projected from the same 3D point in different frames are constant, which is easily violated by illumination variance, reflective surface and texture-less region. Second, there are always some dynamic objects in natural scenes and thus generating occlusion areas, which also affects the success of photometric consistency. To demonstrate the vulnerability of photometric loss, researchers conduct a preliminary study on virtual KITTI because it has dense ground truth depth maps and precise poses. One figure about visualization of the photometric loss shows that even though the ground truth depth and pose are used, the photometric loss map is always not zero due to factors such as occlusions, illumination variance, dynamic objects, etc. To address this problem, the perceptual losses are used in recent work. In line with this research direction, researchers are dedicated to proposing more robust loss items to help enhance the self-supervision signal.
Therefore, the work published in Machine Intelligence Research by researchers from University of Sydney, Tsinghua University and University of Queensland targets to explore more robust cross-view consistency losses to mitigate the side effect of these challenging cases. Researchers first propose a depth feature alignment (DFA) loss, which learns feature offsets between consecutive frames by reconstructing the reference frames from its adjacent frames via deformable alignment. Then, these feature offsets are used to align the temporal depth feature. In this way, researchers utilize the consistency between adjacent frames via feature-level representation, which is more representative and discriminative than pixel intensities. One figure in this paper shows that comparing the photometric intensity between consecutive frames can be problematic, because the intensities of the surrounding region of the target pixel are very close, and the ambiguity may probably cause mismatches.
Besides, prior work proposes to use ICP-based point cloud alignment loss to utilize 3D geometry to enforce cross-view consistency, which is useful to alleviate the ambiguity of 2D pixels. However, rigid 3D point cloud alignment cannot work properly in scenes with the object motion and the resulting occlusion, thereby being sensitive to local object motion. In order to make the model more robust to moving objects and the resulting occlusion areas, researchers propose voxel density as a new 3D representation and define voxel density alignment (VDA) loss to enforce cross-view consistency. Their VDA loss regards the point cloud as an integral spatial distribution. It only enforces the numbers of points inside corresponding voxels of adjacent frames to be consistent and does not penalize small spatial perturbation since the point still stays in the same voxel.
These two cross-view consistency losses exploit the temporal coherence in depth feature space and 3D voxel space for SS-MDE, both shifting the prior “point-to-point” alignment paradigm to the “region-to-region” one. Their method can achieve superior results than the state-of-the-art (SOTA). Researchers conduct ablation experiments to demonstrate the effectiveness and robustness of the proposed losses.
SS-MDE paradigm has become very popular in the community, which mainly takes advantage of cross-view consistency in monocular videos. In Section 2, researchers explore different categories of cross-view consistency used in previous self-unsupervised monocular depth estimation works, including photometric cross-view consistency, feature-level cross-view consistency and 3D space cross-view consistency.
Section 3 introduces methods of the study. In this paper, researchers adopt DFA loss and VDA loss as additional cross-view consistency to the widely used photometric loss and smooth loss. Researchers first propose DFA loss to exploit the temporal coherence in feature space to produce consistent depth estimation. Compared with the photometric loss in the RGB space, measuring the cross-view consistency in the depth feature space is more robust in challenging cases such as illumination variance and texture-less regions, owing to the representation power of deep features. Moreover, researchers design VDA loss to exploit robust cross-view 3D geometry consistency by aligning point cloud distribution in the voxel space. VDA loss has shown to be more effective in handling moving objects and occlusion regions than the rigid point cloud alignment loss.
Section 4 gives a detailed description of the experiments. This section includes seven parts: Part one is about network implementation, network in this paper is composed of three branches for offset learning, depth estimation and pose estimation, respectively; Part two is the introduction of evaluation metrics; Part three is the depth estimation evaluation; Part four introduces ablation study, researchers first ablate the performance of different backbone networks and input resolutions used in their method, the following ablation study is conducted on KITTI using the most lightweight version (R18 LR) to highlight the effectiveness of the proposed two cross-view consistency losses, DFA loss and VDA loss; Part five is the experimental analysis, which includes the effectiveness of VDA loss in handling moving objects, analysis of hyperparameters in VDA loss, analysis of depth feature alignment offset, visualization of depth feature alignment offset, comparison with alignment using optical flow; Part six is the evaluation of generalization ability; Part seven is the model complexity analysis, the model complexity of researchers’ methods is consistent with their baseline method.
This study is dedicated to the SS-MDE problem with a focus on robust cross-view consistency. Experimental results on outdoor benchmarks demonstrate that the method in this paper has achieved superior results than state-of-the-art approaches and can generate better depth maps in texture-less regions and moving object areas. Researchers propose that more efforts can be made to improve the voxelization method in VDA loss to enhance the generalization ability and apply the proposed method to indoor scenes, which will be left for future work.
See the article:
On Robust Cross-view Consistency in Self-supervised Monocular Depth Estimation
Journal
Machine Intelligence Research
Article Title
On Robust Cross-view Consistency in Self-supervised Monocular Depth Estimation
Article Publication Date
21-Mar-2024